Testing product assumptions before you commit to a sprint is one of the few genuine risk-reduction levers available to a product team. Most teams understand this in principle. Most teams do it backwards. The team scopes a feature, plans a sprint, and the first real users become the experiment.
The cost is not just a wasted sprint. When a team builds on a false assumption, it forecloses time that could have gone toward something with better foundations. This post sets out a practical method for identifying which assumptions need testing, classifying them by type, and choosing the cheapest experiment that could disprove each one, with a pass/fail threshold set before the result comes in so the team knows in advance what to do with it.
What assumption testing actually means
Teams use the term loosely. Many product teams describe running a discovery interview as ‘testing assumptions.’ That is not wrong. It misses most of what the practice involves.
Testing product assumptions means identifying specific beliefs your product decision depends on. You then find the smallest possible signal that could disprove each one before you commit significant effort. The word ‘disprove’ matters. A test that can only confirm what you already believe is reassurance-seeking. Reassurance is a legitimate need, not a test.
It helps to draw a brief distinction between assumption and hypothesis. An assumption is a belief your product decision depends on, often unstated. A hypothesis rewrites that assumption in a form a specific experiment can test. Step one of the practice is surfacing assumptions. Step two rewrites the load-bearing ones as hypotheses.
| Assumption (raw belief) | Hypothesis (testable form) |
|---|---|
| Users will like this | Users will change their reporting cadence within 14 days of the feature going live |
| Enterprise will pay more | At least 5 of 8 renewal-independent enterprise accounts accept the indicated premium tier without rejection |
| PMs will trust an AI risk score | At least 4 of 6 beta customers act on the majority of AI-generated alerts in a 4-week window |
| The model can classify project health | Precision above 75% and recall above 70% on 6 months of real project data |
Where the practice sits in existing work
Testing product assumptions goes under several names in existing product writing. Continuous discovery teams call it part of what Teresa Torres, in Continuous Discovery Habits, describes as assumption mapping. Teams rooted in the lean startup tradition treat it as the step that happens inside build-measure-learn before you build. Strategyzer’s taxonomy, developed by David Bland and Alexander Osterwalder in ‘Testing Business Ideas’, pairs assumption mapping with an evidence-strength versus importance matrix. Across all three traditions, the practice is recognisable even where the vocabulary varies.
The four-category framework used below draws from the four product risks Marty Cagan sets out in ‘Inspired’, which are value, usability, feasibility, and business viability. The ‘desirability’ label, used here in place of Cagan’s ‘value’ risk, comes from the IDEO design thinking tradition where desirability, feasibility, and viability form the three lenses of design. Torres adds a fifth category in her current work, which she calls ethics. Most product decisions sit inside the first four categories. The fifth is worth naming because it is routinely under-tested where it does apply.
Assumption testing is not a pre-sprint ritual run once on a feature already scoped. Nor does it substitute for user research, which continues alongside it. Teams also drift toward generating confirming evidence for a direction already chosen, which is the easiest failure mode to miss from inside the team.
The four categories of product assumption
When testing product assumptions, the type of assumption determines the type of test. Running a pricing experiment to check a usability assumption wastes time and produces irrelevant signal. Classifying each assumption first is what makes the rest of the process work.

Desirability
Desirability assumptions cover whether users want the outcome your solution offers. They also cover whether users will use it, and whether it solves the problem you believe they have. ‘Users will seek out a project health dashboard’ is a desirability assumption, as is ‘users prefer automated risk alerts to on-demand reporting.’
Cagan argues in ‘Inspired’ that value risk is the most common reason product efforts fail. Whatever the exact proportion, desirability is where cheap early experiments pay back most reliably. An unloved solution cannot be rescued by better engineering or sharper pricing.
Feasibility
Feasibility assumptions are about whether you can build the solution at the quality and scale the use case requires. ‘The model can classify project health accurately from existing data’ is a feasibility assumption. So is ‘integrating with the five calendar tools target customers use is achievable within a sprint.’
Three sub-types tend to hide under one heading. Technical feasibility covers whether the thing can be built at all. Data feasibility covers whether the data you need exists, is labelled, and is representative, which is an essential question for any AI-assisted feature. Operational feasibility covers whether this team can deliver within the constraints of this timeline. A team that ships high-quality microservices every week may still find that training a classifier on six months of sparse, inconsistently tagged project data is a different problem entirely, because the data rarely looks the way the model needs it to.
Viability
Viability assumptions cover whether the solution can generate value for the business. Pricing, cost-to-serve, unit economics, channel fit, legal, and compliance questions all live here. Whether enterprise customers will pay a premium tier for this feature is a viability assumption. So is whether enterprise legal teams will permit AI analysis of project data.
Viability is easiest to surface early when it is treated as a product question rather than a finance one. A feature priced at a premium tier in the spreadsheet can meet a very different reception when an enterprise buyer sees the quote, and discovering that after engineering spend is an expensive way to learn it.
Usability
Usability assumptions are about whether users can get value from the solution without intervention. Examples include whether project managers can interpret a risk score and decide on next actions without guidance, or whether users can configure automated alerts without contacting support. Discoverability also sits under usability, since it covers whether users even find the feature in the first place.
Testing usability assumptions happens before you build, using prototypes. It is a different activity from quality assurance or user acceptance testing, both of which come later and check whether an already-built feature behaves correctly. A usability assumption test asks a harder question. Should the feature be built at all, given what the team observes users try to do with it.
A five-step process for testing product assumptions
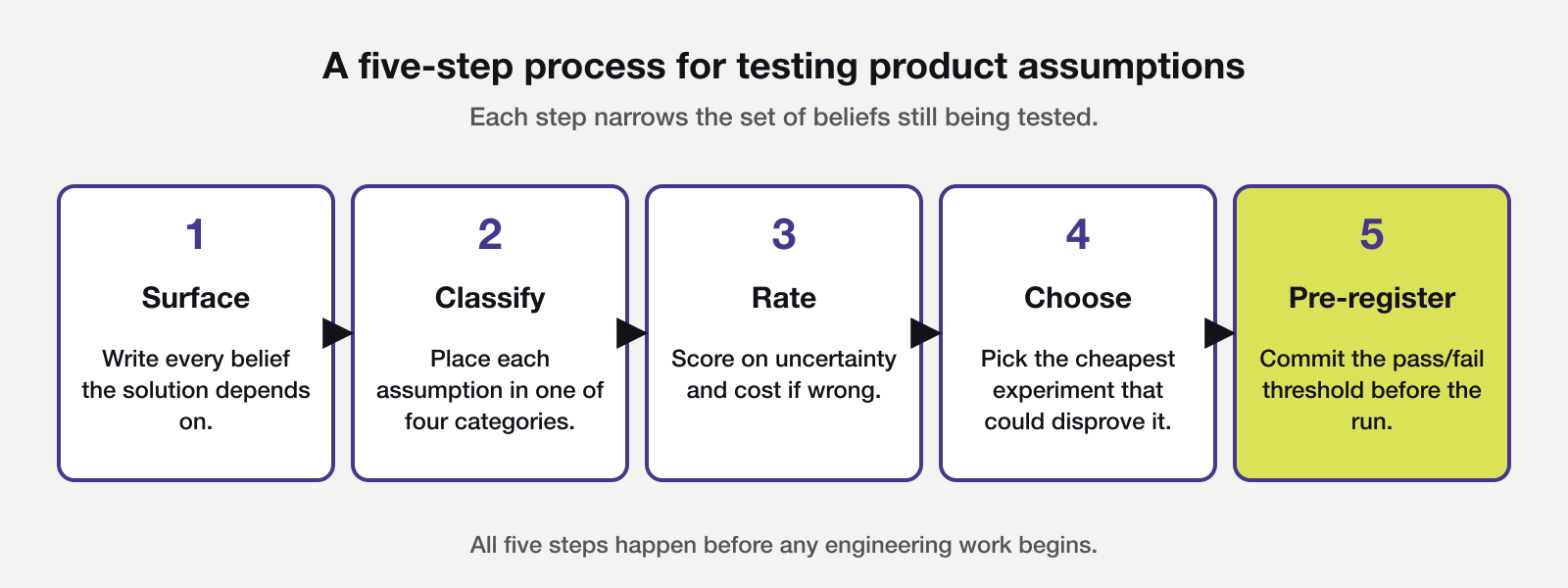
Start by surfacing every assumption your proposed solution depends on. Write each as a specific, falsifiable statement about user behaviour or business conditions. Rather than ‘users will like this,’ write ‘users will change their reporting cadence as a result of this feature.’ Vague assumptions produce vague tests. For a feature with a typical scope, aim for eight to fifteen assumptions. Fewer than five usually signals that load-bearing assumptions are still implicit, while more than twenty means implementation details have crept onto the list.
With the list in front of you, classify each assumption by type using the four categories above. This is a short group exercise rather than a solo task, and the right group is cross-functional, bringing together product, engineering, design, and a commercial representative who knows the buyer. Disagreement about classification is the most useful part of the session. It surfaces implicit assumptions about whose problem this actually is.
Next, rate each assumption on two dimensions. One is how certain the team is that it is true, and the other is what the cost would be if it turns out to be false. High uncertainty combined with high cost defines the priority order when testing product assumptions in earnest. Those assumptions are the riskiest ones, commonly referred to in product writing as the Riskiest Assumption Test, or RAT. They get tested first, before the sprint and before any engineering work begins.
Choosing and pre-registering the experiment
For the highest-priority assumption, choose the cheapest experiment that could actually disprove it. Cheapest means fastest and lowest engineering effort, not lowest rigour. An experiment that can only confirm a direction already chosen does not produce decision-relevant signal, and it often produces something worse, which is false confidence.
Before running the experiment, write down the pass/fail threshold. What result would cause you to proceed? What result would cause you to change or abandon the solution? Commit to both answers before the experiment starts, then read the result against the threshold you wrote, not the outcome you hoped for. Testing product assumptions with a pre-registered threshold is the single practice that separates an assumption test from post-hoc rationalisation.
Matching experiment types to assumption categories
Different assumption types suit different experiment designs. Using the wrong method is a common source of weak results when testing product assumptions across a roadmap. The table below pairs each category with its best experiments, a short example, and the failure mode when the pairing is broken.
The experiment matrix
| Category | Primary experiment | Example | Common failure when misapplied |
|---|---|---|---|
| Desirability | Behavioural tests: fake-door, Wizard of Oz, concierge MVP, and Mom-Test interviews anchored on past behaviour | Fake-door ‘Enable auto-alerts’ button measures click-through against a baseline | Hypothetical questions produce false positives; users ask for features they later do not adopt |
| Feasibility | Technical spike or narrow proof-of-concept, sized to answer one question and stop | Prototype a classifier on a representative data sample, measure precision and recall | Thresholds set by convention, not by the feature’s real need |
| Viability | Pricing page tests, letters of intent, pricing conversations held away from renewals, early legal discovery | Discuss a premium tier with 8 enterprise accounts outside active renewal | Discovering post-launch that the feature cannot be deployed in regulated industries |
| Usability | Unmoderated prototype tests with five to eight representative users, per Jakob Nielsen’s heuristic | Five PMs walk through a prototype unaided; observers record unprompted next actions | Checking an already-built feature rather than whether to build it at all |
Two caveats on behavioural experiments
Two caveats shape how far these experiment types will carry you. A concierge MVP tells you the outcome is achievable, not that the team can automate it at scale. A fake-door test creates a genuine user expectation of a feature that does not exist, so decide in advance how you will communicate with users who click. Five to eight users will surface the most significant usability failures but cannot replace broader validation where the user population is diverse or the context highly variable.
Four patterns that reduce signal quality
Four patterns appear regularly in assumption-testing work. Recognising them in advance makes it easier to design experiments that generate decision signal when testing product assumptions in earnest.
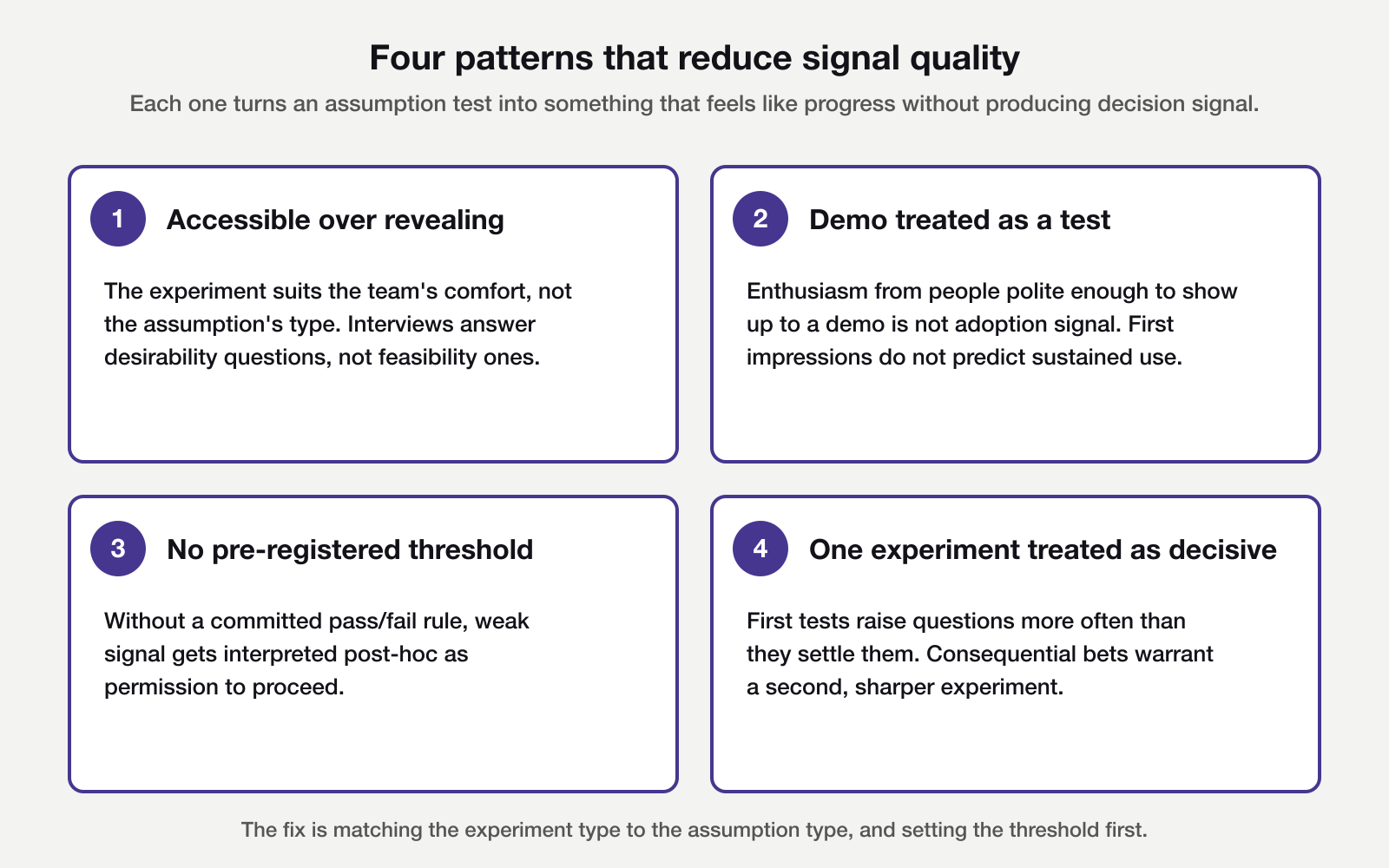
The most common pattern is prioritising the most accessible experiment over the most revealing one. Discovery interviews are easy to arrange and produce clear outputs. If the highest-risk assumption concerns feasibility or viability, an interview generates no signal on it. The type of assumption determines the type of experiment.
A related pattern is treating a demo as a test. Eight enthusiastic responses to a prototype demo are not eight data points on adoption. They are eight data points on first impressions from people polite enough to show up to a demo. The distinction matters most when the assumption concerns adoption or behaviour change, not initial appeal.
Running experiments without a pre-defined pass/fail threshold makes results hard to act on. If a fake-door test returns 12% click-through, is that a pass? The answer is only clear when the threshold was set before the experiment started. Committing to it in advance keeps the result independent of what the team was hoping to see.
Treating a single experiment as decisive is the fourth pattern. One fake-door with a 12% click-through is an observation, not a finding. For consequential bets, assume the first test raises questions rather than answers them, and budget for a second confirmatory experiment where the stakes justify it. The same applies when a test under-recruits. Results from three interviews are directional only, and should inform the next round of testing product assumptions rather than conclude the exercise.
A worked example
A product team at a B2B project management tool is considering an AI-powered ‘project health score’ feature. It would identify at-risk projects and flag them to stakeholders. Before scoping a sprint, the team runs a two-hour assumption-mapping session. Product, engineering, design, and the enterprise account lead attend.
The team surfaces fourteen assumptions in the first half of the session, then collapses them to eight after removing duplicates and implementation details. One classification disagreement matters. ‘PMs will trust an AI risk score enough to act on it’ sits on the boundary between desirability and usability. The group settles on desirability, because the test needs to reveal whether PMs want to rely on the score, not whether they can read it.
Each assumption then receives two scores. One is uncertainty, meaning how confident the team is that the belief is true, on a three-point scale. The other is cost if wrong, meaning the engineering and opportunity cost should the assumption turn out to be false.
The eight assumptions in full
The table below records the eight assumptions, their type, a risk rating that combines the two scores, the experiment the team chose, and the pass/fail threshold the session defined.
| Assumption | Type | Risk | Experiment | Pass/fail threshold |
|---|---|---|---|---|
| PMs want automated risk alerts, not just on-demand reports | Desirability | High | Fake-door ‘Enable auto-alerts’ button on the reports page, shown to PMs with weekly visits over 4 weeks | 15% click-through across at least 100 eligible PMs; baseline for adjacent CTA is 6% |
| PMs will trust an AI risk score enough to act on it | Desirability | High | Concierge MVP; analyst scores projects weekly for 6 beta customers; record whether alerts prompt action | 4 of 6 customers act on the majority of alerts (directional, not decisive) |
| Stakeholders (not just PMs) want project health visibility | Desirability | Medium | 5 stakeholder interviews exploring current reporting behaviour | 4 of 5 confirm manual compilation; 3 rate it worth solving |
| ML model can classify project health with sufficient accuracy | Feasibility | High | Technical spike; prototype against 6 months of historical data | Precision above 75% and recall above 70%, thresholds set against the team’s estimate of tolerable false-positive rate |
| Integration with 4 target project tools is achievable within sprint capacity | Feasibility | Medium | Technical discovery; review each API, prototype one integration | All 4 APIs provide required fields; no integration exceeds 5 days |
| Enterprise customers will pay a premium tier for this feature | Viability | High | Pricing conversation with 8 enterprise accounts outside active renewal | 5 of 8 open to upgrading at the indicated tier; no outright rejections |
| Enterprise data governance will permit AI analysis of project data | Viability | High | Compliance discovery with 6 enterprise legal contacts across 3 segments | No outright blockers in a majority of conversations; architecture changes required in at most 2 |
| PMs can interpret a risk score and decide next actions without guidance | Usability | Medium | Prototype test; 5 PMs walk through, observe unaided navigation | 4 of 5 identify highest-risk project; 3 articulate next action unprompted |
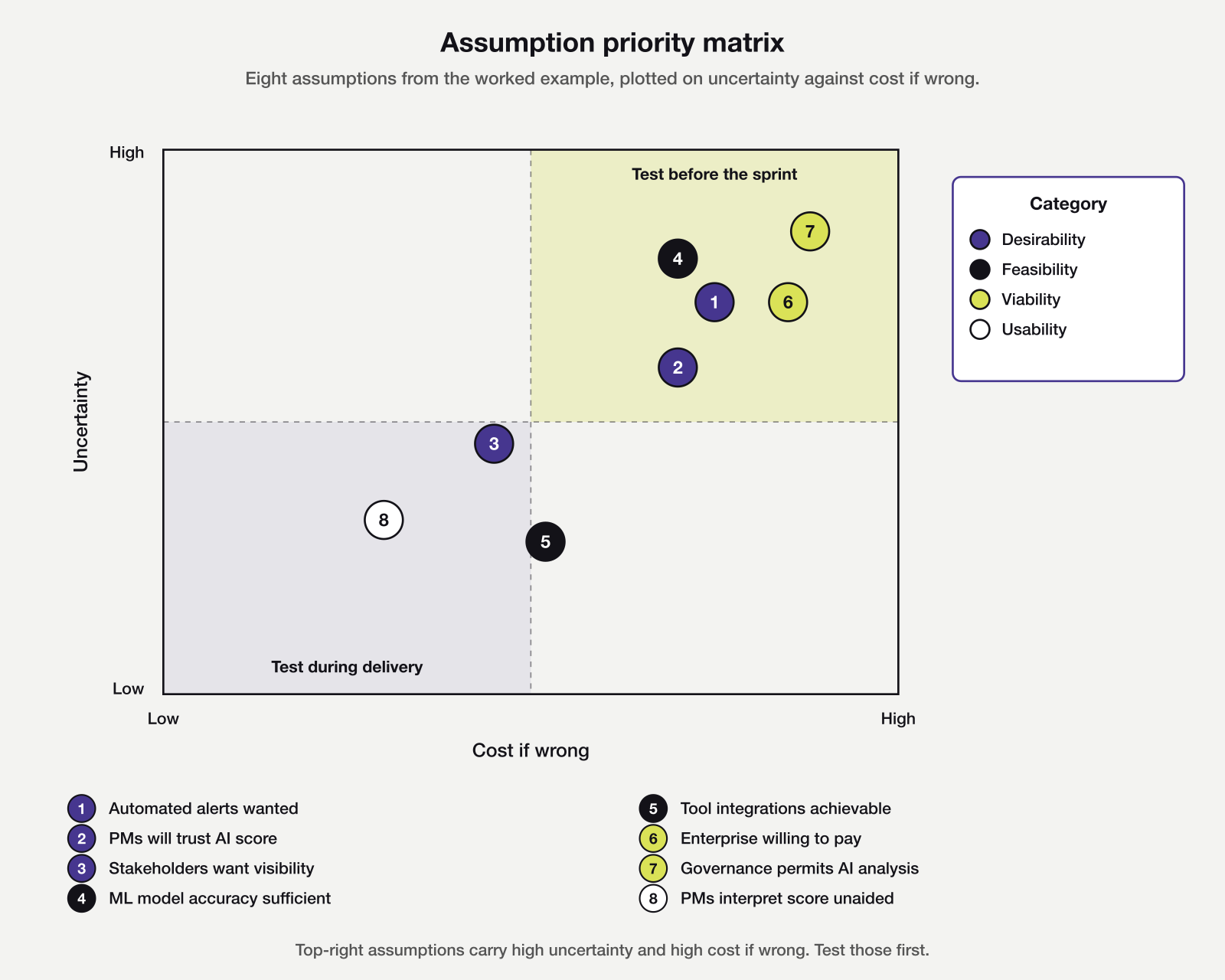
Plotting the eight assumptions on the uncertainty versus cost-if-wrong matrix makes the priority order concrete. Five land in the top-right quadrant and warrant pre-sprint testing. Three sit below the threshold and wait until the team has chosen a solution direction.
How the experiments played out
Of the five in the top-right quadrant, governance and ML accuracy sit nearest the corner. Both carry the highest cost if wrong and the least certainty about the outcome. The team commits to those two experiments first, alongside the enterprise pricing test, since all three can run in parallel without engineering resource.
The viability experiment returns a sharp signal quickly. Four of the six enterprise legal contacts say data sovereignty rules would block the feature in its current form without architecture changes well beyond the original scope. That finding reshapes the approach rather than ending the idea. The team pauses the AI-driven architecture for enterprise customers, keeps the experiment open for two further conversations to confirm the pattern, and revisits desirability under a different solution design that keeps data on-premises.
That governance test cost three email exchanges and two calendar invites. The sprint it prevented would have cost six weeks.
A test that passes
A positive result is worth showing briefly, because it introduces an easy mistake. The feasibility spike on the ML model runs against six months of historical project data over two weeks. Precision lands at 79%, recall at 73%. Both clear the pre-set threshold, but only just.
The team proceeds, and commits to monitor precision and recall on live data in the first month after release, with a defined trigger to pause rollout if either figure slips below the threshold. The useful pattern runs one step further than ‘the test passed, therefore build.’ The test passed, and here is what the team will watch to know whether the assumption still holds.
Reading the results
Testing product assumptions generates results that need honest interpretation. Two questions decide whether a result is worth acting on.
First is whether the result answers the assumption. A customer interview in which a user says ‘yes, that sounds useful’ does not answer a desirability assumption. The question is whether they would change their reporting cadence. Treat positive-feeling results that miss the specific assumption as context, not as permission to proceed. Then design a test that addresses the question directly.
Second is whether the signal is strong enough to proceed, given the stakes. A fake-door test with 4% click-through on a feature requiring a three-sprint build does not justify the investment. The same result on a half-day build might. The pass/fail threshold set before the experiment accounts for this. What it prevents is post-hoc rationalisation of weak signal into permission to proceed.
If your team uses an opportunity solution tree to map the problem space, testing product assumptions slots into the solution layer. Each solution branch generates a set of assumptions, and the team tests those before choosing a branch for development. Where an impact mapping session is the primary planning artefact, the same principle applies. The deliverables on an impact map carry behaviour-change assumptions that deserve testing before they reach a roadmap.
When the result is ambiguous
If a result is ambiguous, run a second experiment to resolve it. An extra week of experimentation usually costs less than a sprint spent building the wrong thing, and considerably less than explaining to stakeholders why the team pulled the feature. A second experiment also gives the team a chance to test a sharper version of the question, now that the first result has revealed where the original was fuzzy.
The gap between running experiments and testing product assumptions that matter most is rarely about willingness. Familiar experiments on assumptions you already understand produce results quickly, which feels like progress. The harder work is designing a test for the thing that could change direction, whether a governance rule, a pricing ceiling, or the behaviour that does not change even when users say it will. The question that surfaces those tests is worth asking before the first planning meeting, not after the feature ships. What would it take for this assumption to be false, and what is the cheapest way to find out?