
The feedback loop problem with AI-generated code
Test-driven development and AI coding tools seem, at first glance, to pull in opposite directions.
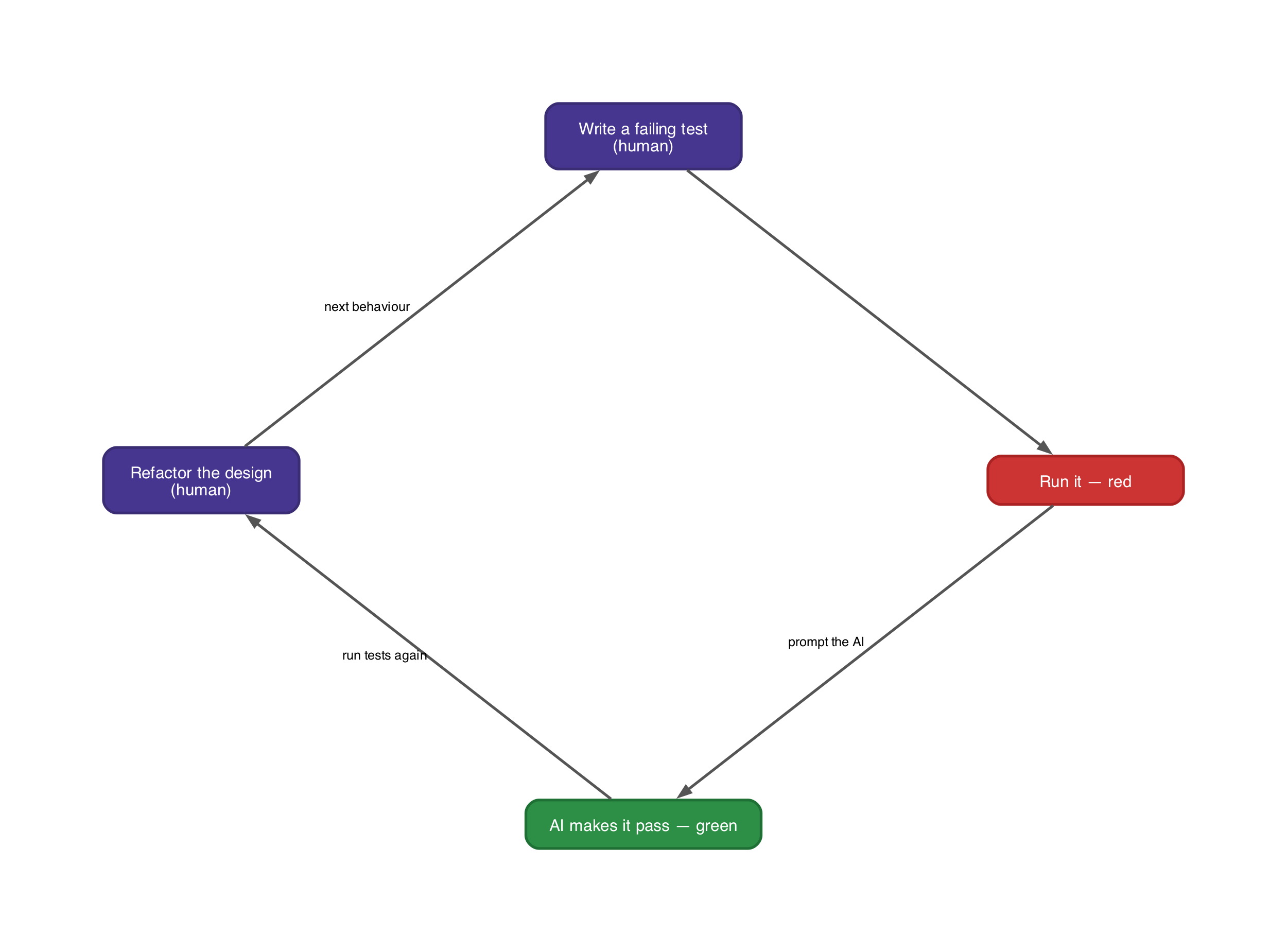
Test-driven development asks you to slow down. Write a failing test. Write the minimum code to pass it. Refactor. Repeat.
AI tools do the opposite. They produce dozens of lines in seconds, offering plausible solutions before you have fully stated the problem.
The temptation is obvious. If the AI can produce a working function in ten seconds, why spend five minutes on a test first? The reasoning is understandable, and it is wrong.
The missing element in AI-assisted development is not speed or capability. It is feedback. When an AI generates code, nobody holds a mental model of what that code does until someone reads it. The output is a black box.
It may work. It may contain a subtle bug that surfaces three days later. Without a way to verify intent against implementation, you accumulate code without accumulating confidence.
Think of it like commissioning a painting by describing it over the phone. The artist may be talented. They may even get it right. But until you see the canvas, you have no idea whether the result matches what you pictured. A test is the sketch you send them first.
In my experience, most developers who have used AI coding tools for a few weeks have hit this pattern. The AI produces something that looks right, passes a manual check, gets committed, and breaks something else later. The code was correct on the surface. It was also wrong in a way that only a test would have caught.
What test-driven development actually does (that AI cannot replace)
Most people think test-driven development produces tests. This is true but secondary. The primary function of test-driven development is to force you to think about behaviour before writing any code.
In Test-Driven Development: By Example, Kent Beck describes the practice as a way to transform fear into boredom, turning the anxiety of uncertain code into the mundane confidence of passing tests. That framing holds up well in the age of AI-generated code. The test is a specification. Writing it is an act of design.
When you write a test first, you answer three questions. What should this unit do? Where are the boundaries and edge cases? How will you know it works? The test answers all three before a line of code exists.
AI coding tools skip all three. They infer intent, generate code, and leave you to check it. The result is code built to a specification that was not stated. If your intent differs from what the AI guessed, you find out in production.
Test-driven development inverts this. You state the specification first, in a form that can run automatically. The AI then becomes a tool for satisfying a known specification, not for guessing at an unknown one.
A worked example
You need a function that calculates shipping costs based on weight and destination zone. Without TDD, you might prompt an AI with ‘write a function that calculates shipping costs.’ The AI will produce something plausible.
But does it handle a weight of zero? Does it distinguish domestic from international zones? Does it round to two decimal places? You will not know until you read every line and trace the logic yourself.
The first test as specification
With test-driven development, you start differently. You write a test first.
import pytest
from shipping import calculate_shipping, Zone
def test_domestic_standard_shipping():
cost = calculate_shipping(weight_kg=2.5, zone=Zone.DOMESTIC)
assert cost == pytest.approx(4.95)A note on pytest.approx here. Shipping costs are money, and floating-point arithmetic does not reliably produce exact decimal results. In production you would likely use Decimal throughout, but pytest.approx keeps the example readable.
This test does several things before the AI writes a single line of code. The function name is pinned down. The inputs are defined, with weight in kilograms and a Zone enum that constrains destination to valid values. Expected output is stated explicitly. Six lines of test code, and you already have a specification.
Run it. It fails. No function exists yet. Now prompt the AI with ‘make this test pass.’ The AI has a concrete target. It can produce an implementation that passes this specific assertion, and you can verify the result instantly by running the test again.
Triangulation, or how tests carve the implementation
Here is where something interesting happens. An AI prompted with ‘make this test pass’ could satisfy it by returning a constant, return 4.95. That implementation is technically correct. It passes the test. It is also obviously useless for any other parcel.
This is fine. In fact, it is the point. Beck calls this technique triangulation. You start with a degenerate implementation that passes your first test, then add more tests that force the code to become real.
Think of it like sculpting. The first test is the first chisel strike, removing the obviously wrong material but leaving a vague block. Each subsequent test is another strike from a different angle. After enough strikes, the shape of the real implementation emerges.
The second test makes the first strike from a new angle.
def test_international_shipping_is_more_expensive():
domestic = calculate_shipping(weight_kg=2.5, zone=Zone.DOMESTIC)
international = calculate_shipping(weight_kg=2.5, zone=Zone.INTERNATIONAL)
assert international > domesticNow return 4.95 fails. The AI has to make the zone parameter actually matter. The implementation is forced from a constant towards a lookup. One more test, and the weight parameter earns its place too.
def test_heavier_parcel_costs_more():
light = calculate_shipping(weight_kg=1.0, zone=Zone.DOMESTIC)
heavy = calculate_shipping(weight_kg=5.0, zone=Zone.DOMESTIC)
assert heavy > lightThree tests, three angles. The implementation can no longer hide behind a constant or a flat rate. It must actually calculate shipping based on weight and zone. Each test removed a degree of freedom until only the real logic remained.
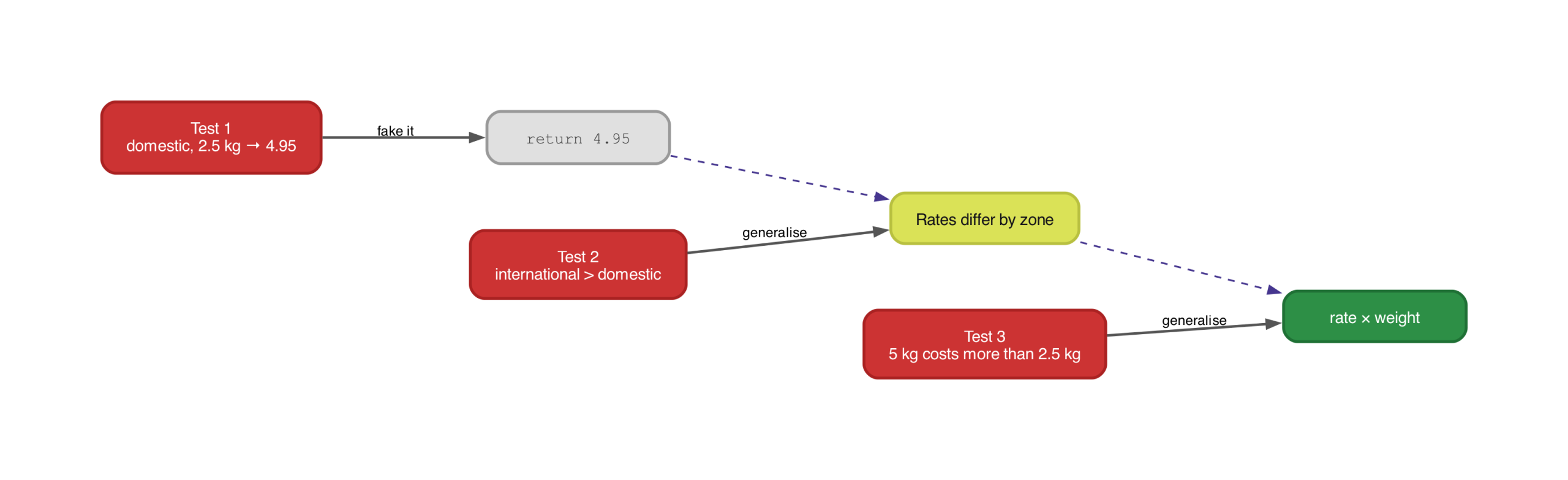
This matters more with AI tools than it does with a human developer. A human writing the code would likely type the real implementation straight away because they already know the formula. An AI prompted with a single test has no reason not to take the cheapest shortcut. Triangulation gives it progressively tighter constraints until the shortcut and the real solution are the same thing.
Edge cases as design decisions
Continue with boundary tests, using pytest’s exception assertions.
def test_zero_weight_raises_error():
with pytest.raises(ValueError, match="Weight must be positive"):
calculate_shipping(weight_kg=0, zone=Zone.DOMESTIC)
def test_negative_weight_raises_error():
with pytest.raises(ValueError, match="Weight must be positive"):
calculate_shipping(weight_kg=-1, zone=Zone.DOMESTIC)Each of these is a design decision wearing a test’s clothing. Zero weight is an error, not a free shipment. Negative weight is invalid. The Zone enum makes invalid zones a non-issue at the type level. Without these tests, the AI would make these decisions for you, and its choices might not match yours.
A test is a better prompt than natural language. ‘Write a function that calculates shipping costs’ is ambiguous. A set of failing tests is precise. The AI has no room to misinterpret your intent because your intent is encoded as executable assertions.
Why AI-generated tests defeat the purpose
A common response is to skip test-driven development and let the AI generate both the code and the tests. This is circular. If the same system writes the implementation and the specification, the specification will reflect the implementation’s assumptions, including its bugs.
Imagine hiring a builder and then asking that same builder to inspect their own work. They are not going to flag the corners they cut. An AI that writes a shipping function returning zero for zero weight will also write a test that asserts zero weight returns zero. The test passes, but the behaviour is still wrong if your business rule says zero weight should be rejected.
A test exists to show that code does what it should do, not merely what it does do. That ‘should’ comes from your understanding of the domain and the edge cases. You cannot get it from the code itself.
AI tools are still useful for testing, though. They can generate test scaffolding, produce realistic test data, and suggest edge cases you might have missed. But the core assertions, the statements about what correct behaviour looks like, must come from your understanding of the requirement.
Design pressure and what it reveals
One of TDD’s less discussed benefits is design pressure. Writing tests first reveals problems in your design that you would not otherwise see until much later. If a class is hard to test, that difficulty is information. It usually means the class has too many responsibilities, too many dependencies, or unclear boundaries.
AI-generated code often sidesteps this signal. Without explicit guidance, an AI coding tool will produce a function that works regardless of whether it is well-designed. It will happily generate a 200-line method with six parameters and three side effects. The prompt asked for a function that does X. The function does X.
You can teach an AI agent to prefer smaller functions through project configuration and custom instructions, but even then, the test is what makes the preference concrete. A rule that says ‘keep functions short’ is a suggestion. A test that becomes painful to write for a long function is a physical constraint.
When you write the test first, the design pressure comes back. A test for a 200-line function with six parameters is painful to write. You need extensive setup, multiple assertions, and careful management of side effects. That pain is the test telling you the design is wrong. The fix is to break the function into pieces that are each simple to test.
Without tests exerting this pressure, there is no feedback signal pushing AI-generated code towards smaller, focussed units. The codebase drifts towards the software equivalent of a junk drawer, everything in one place, nothing easy to find. Tests act as a counterweight, pulling the design towards smaller, cohesive units with clear interfaces.
Refactoring and the patience to wait for the right abstraction
Refactoring means improving code structure without changing its observable behaviour. The ‘without changing behaviour’ part requires tests to verify. Without tests, refactoring AI-generated code is risky.
You ask the AI to restructure something. It produces a new version. You have no way to confirm it does the same thing as the old one. So people stop refactoring.
The code works, and nobody wants to touch it. It becomes the load-bearing wall that everyone routes around but nobody dares inspect.
With a test suite, refactoring is safe. But knowing when to refactor matters as much as knowing how.
Tolerating duplication until the pattern emerges
AI coding tools have a habit of extracting abstractions at the first whiff of duplication. They see two similar blocks and immediately reach for a helper function. This is often premature. The first time you see duplication, you do not yet know whether it is accidental or structural. Pulling out an abstraction based on two examples is like concluding that all swans are white because you have seen two of them.
Suppose the shipping function grows. A new requirement arrives for a fuel surcharge. The AI produces something like this.
def calculate_shipping(weight_kg: float, zone: Zone) -> float:
if weight_kg <= 0:
raise ValueError("Weight must be positive")
base_rate = RATES[zone]
shipping = base_rate * weight_kg
fuel_rate = FUEL_RATES[zone]
fuel_surcharge = fuel_rate * weight_kg
return round(shipping + fuel_surcharge, 2)Two blocks follow the same pattern. Look up a rate by zone, multiply by weight. An AI would likely extract a helper immediately. Resist.
Two instances is a coincidence, not a pattern. You do not yet know whether every future cost component will follow the same shape.
Then insurance arrives, and it does follow the same shape.
def calculate_shipping(weight_kg: float, zone: Zone) -> float:
if weight_kg <= 0:
raise ValueError("Weight must be positive")
base_rate = RATES[zone]
shipping = base_rate * weight_kg
fuel_rate = FUEL_RATES[zone]
fuel_surcharge = fuel_rate * weight_kg
insurance_rate = INSURANCE_RATES[zone]
insurance = insurance_rate * weight_kg
return round(shipping + fuel_surcharge + insurance, 2)Extracting the real pattern
Three instances. Now the real abstraction is visible. Every cost component is a rate looked up by zone, multiplied by weight. That is not a guess based on two examples. It is a pattern confirmed by three.
COST_COMPONENTS = {
"shipping": RATES,
"fuel": FUEL_RATES,
"insurance": INSURANCE_RATES,
}
def calculate_shipping(weight_kg: float, zone: Zone) -> float:
if weight_kg <= 0:
raise ValueError("Weight must be positive")
total = sum(
rates[zone] * weight_kg
for rates in COST_COMPONENTS.values()
)
return round(total, 2)The tests do not change. They do not care how the function is structured internally. They care that domestic 2.5 kg still costs 4.95, that international is more expensive, that heavier parcels cost more, and that zero weight is rejected. The refactoring is safe because the tests pin the behaviour in place while you reshape the code underneath.
Left to its own devices, an AI will eagerly extract a calculate_component helper the moment it sees two similar blocks, before you know whether the pattern is real. Sometimes the third requirement breaks the pattern entirely. Perhaps insurance is a flat fee, not weight-based.
If you had already extracted an abstraction assuming all components are rate × weight, you now have to bend it with conditionals and special cases. Sandi Metz put it well. Duplication is far cheaper than the wrong abstraction. Wait for the third example. Let the real pattern announce itself.
This does not mean AI tools are incapable of refactoring discipline. Modern AI coding agents can be guided through project-level configuration files, custom instructions, and reusable skill definitions that encode engineering principles like ‘do not extract until you see three instances’ or ‘prefer duplication over the wrong abstraction.’
The discipline is transferable; you just have to teach it explicitly rather than assuming the tool will intuit it. The tests remain the verification mechanism. They confirm the AI followed the guidance correctly, regardless of how sophisticated that guidance is.
The understanding you lose when you stop writing the code
There is a cost to AI-generated code that does not show up in any metric. When a developer writes code by hand, they build a mental model of the system as a side effect. They know where the boundaries are, which module handles what, where the assumptions live. This understanding is not documented anywhere. It lives in the heads of the people who did the work.
When an AI writes the code and a human reviews it, the mental model is shallower. When the AI writes the code and nobody reviews it carefully, the mental model barely exists.
Think of it like inheriting a house you did not build. Everything works. The lights turn on, the water runs, the heating fires up. But you do not know where the pipes run behind the walls, which walls are structural, or what the previous owner bodged in the loft.
It is fine until something breaks. Then you are paying someone to open up walls exploratorily, tracing wires that nobody mapped.
When the lack of understanding becomes operational risk
This compounds. Each piece of AI-generated code that nobody deeply understands becomes a piece of the system that nobody can reason about confidently. When something fails at 2am, the on-call engineer cannot rely on familiarity. They are reading the code for the first time, under pressure, with a clock running.
When architecture decisions need to be made, nobody has the intuitive sense of where the system’s weight sits. Every question becomes an archaeology exercise.
Is this a real operational risk or just philosophical discomfort? Both, but the operational risk is the one that should worry organisations. Teams that outsource all implementation to AI and skip the feedback loop will, over time, lose the ability to reason about their own systems.
Incident response slows down. Architectural decisions become conservative because nobody trusts their understanding enough to make bold ones. New team members cannot be onboarded through conversation because nobody can explain the system. They can only point at it.
Tests as collective memory
The counterargument deserves honest consideration. Large systems have long been too complex for any one person to hold in their head. Developers have routinely inherited code they did not write. And AI tools can explain code on demand.
You can ask an AI ‘what does this module do?’ and get a reasonable answer. Perhaps the right model is not ‘understand everything’ but ‘understand the contracts and boundaries, and trust the tests to verify the rest.’
That is where TDD earns its place again. Writing a test forces you to engage with the behaviour of a piece of code, even if you do not write the implementation yourself. You may not know how the shipping function calculates its result, but you know what it should return for a 2.5 kg domestic parcel. It must reject zero weight. International must cost more than domestic.
The test suite becomes a kind of collective memory, a record of every decision the team made about how the system should behave. It is not the same as the deep understanding you get from writing every line, but it is vastly better than the nothing you get from accepting AI output unchecked.
The practical question for teams is not whether to use AI tools. That decision is already made. The question is how much understanding you are willing to let go of, and what mechanisms you put in place to preserve the understanding that matters.
Tests are the most reliable of those mechanisms. They are executable, automated, and they scream when something changes. Comments rot. Documentation drifts.
Architecture diagrams become fiction. Tests stay honest or they fail.
Making this work day to day
The adjustments needed to use test-driven development with AI tools are small. Write the test first and then let the AI satisfy it. A failing test is a better prompt than anything you could type in natural language, and running the suite after every AI-generated change catches the unintended modifications that AI tools sometimes make to files you did not ask it to touch.
Beyond that, the main shift is one of trust. I treat AI-generated code the way I would treat code from a developer I have not worked with before. It might be correct. It might be subtly wrong. The test suite is how I find out.
And because AI-generated code tends to accumulate structural problems faster than hand-written code (the AI optimises for local correctness, not codebase coherence), I refactor more aggressively than I would otherwise, leaning on the tests to confirm that each restructuring preserved behaviour.
When to ease off
Strict test-driven development is not the right fit for every situation. Exploratory prototyping, spike work, and throwaway scripts are contexts where writing tests first slows you down without proportional benefit. Tests carry maintenance cost too.
A brittle test suite that tests implementation details rather than behaviour can impede development more than it helps. The discipline is in knowing when to apply TDD rigorously and when a lighter touch is enough. With AI-generated code, the balance tips towards rigour. Unverified AI output compounds its costs faster than hand-written code you understood as you typed it.
On your next feature, try this. Write one failing test before you open your AI coding tool. Run it. Watch it fail. Then let the AI make it pass.
That single loop will tell you more about the value of test-driven development in an AI-assisted workflow than any article can.